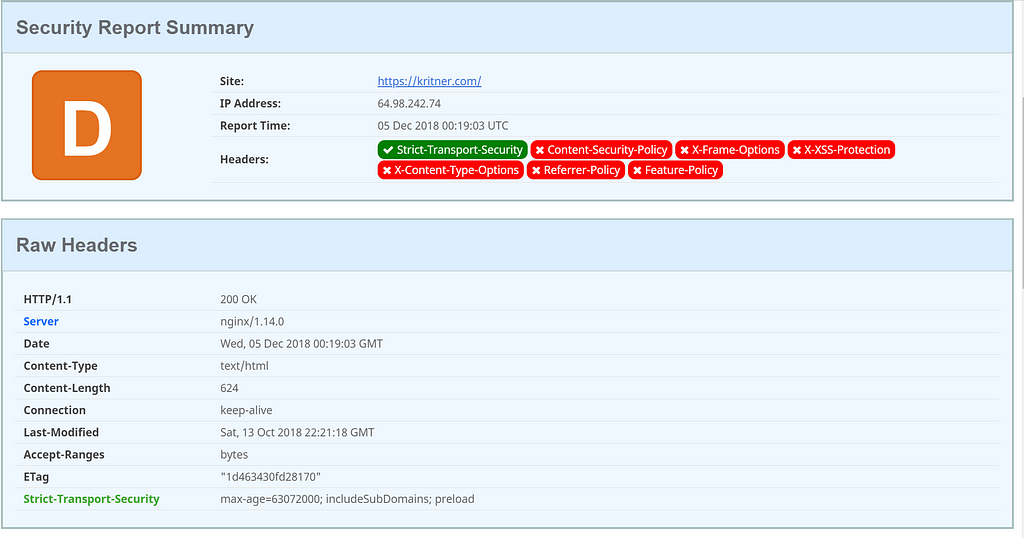
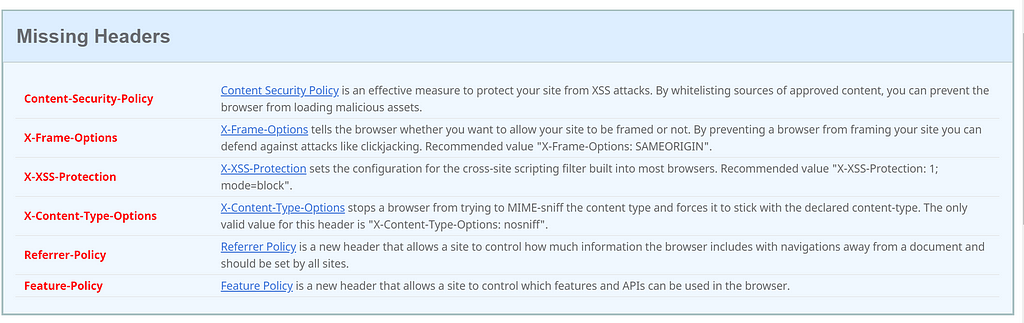
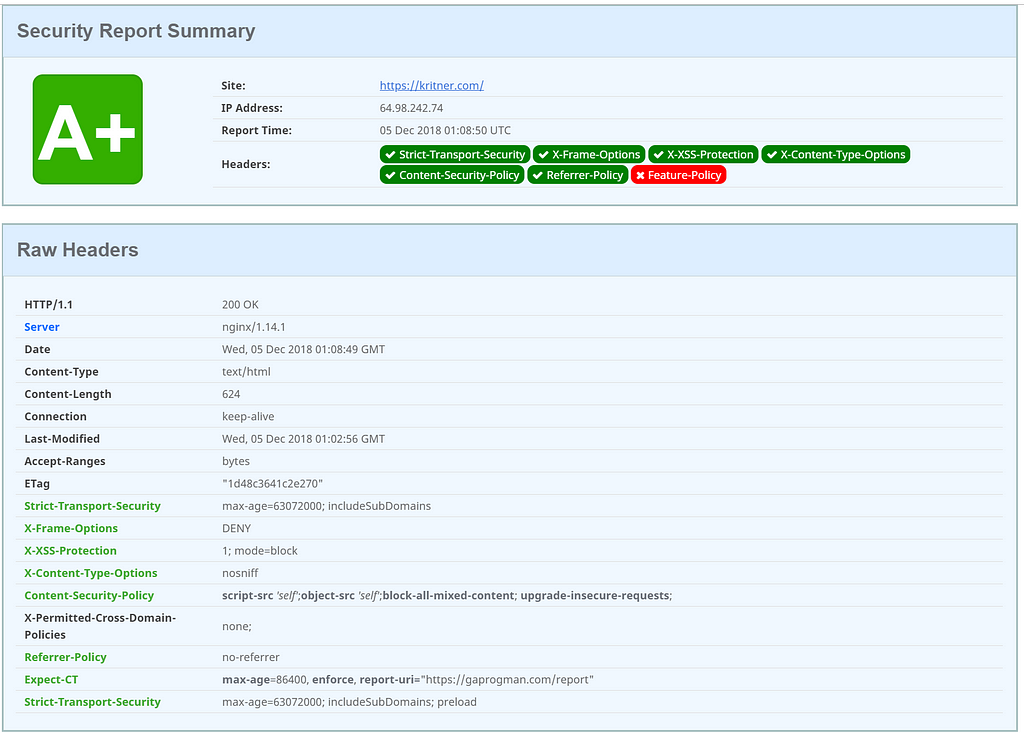
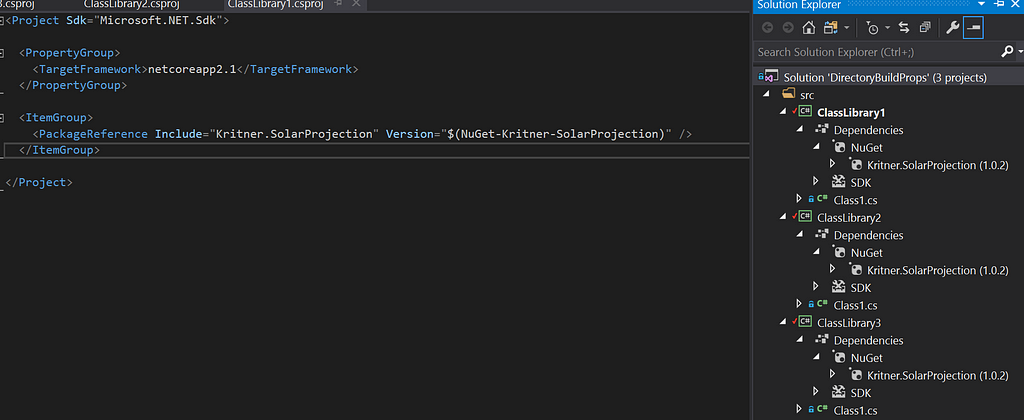
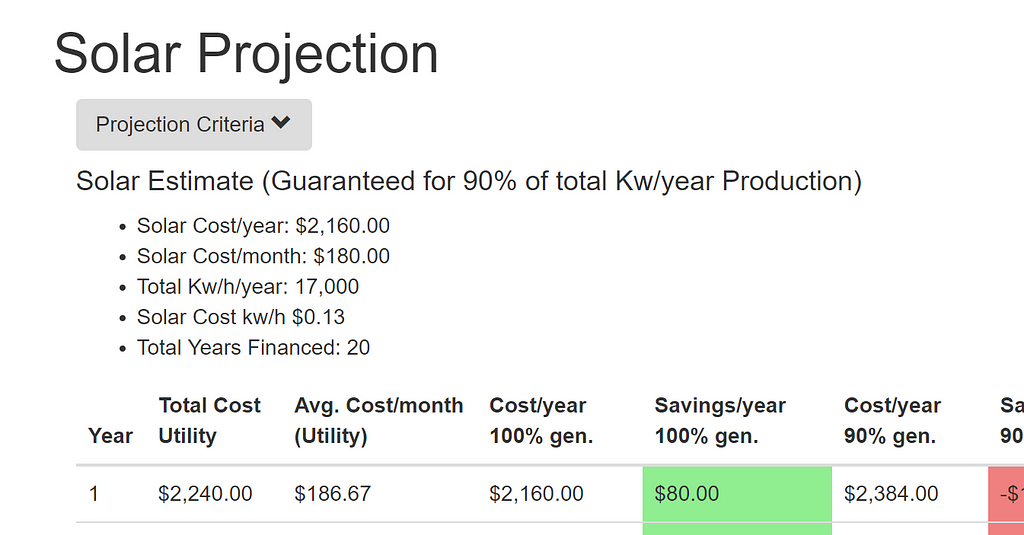
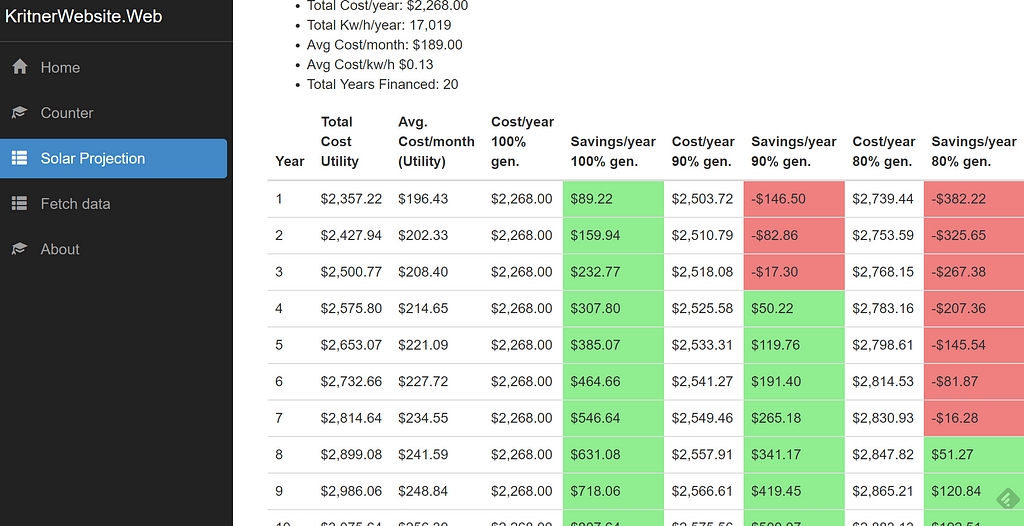
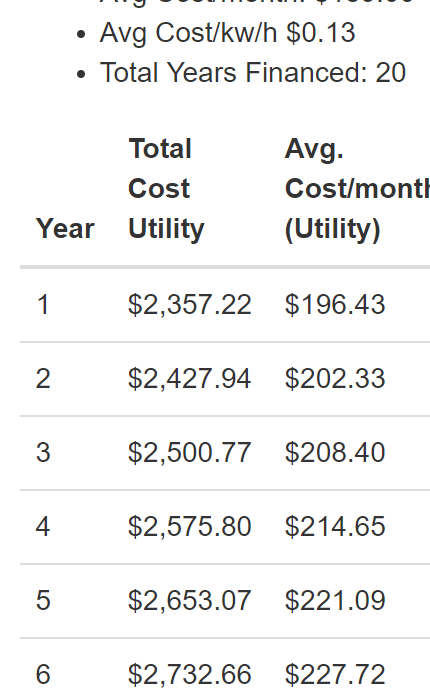
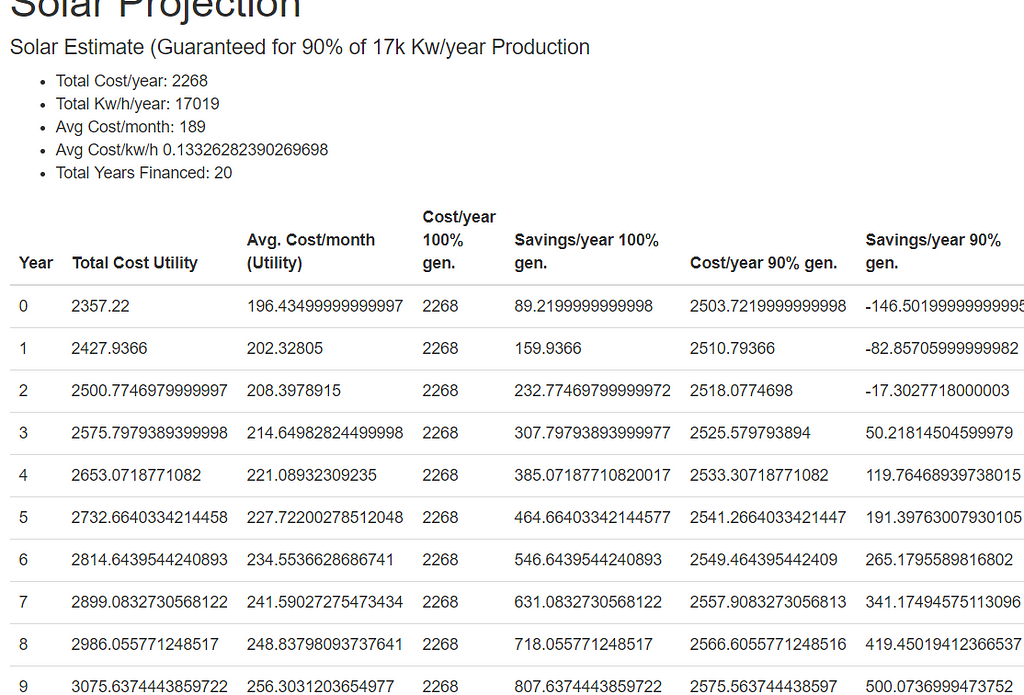
The ketogenic diet is a different way to approach food, and energy from food. In the typical American diet, one receives most of the energy they get from food via carbohydrates. On the ketogenic diet, most of your energy is derived from fat rather than carbs.Keto overview
The ketogenic diet is regarded as a high fat, moderate protein, and low carb diet. To stay in ketosis, the state your body is in when burning fat for energy, you must generally stick between 20g and 50g net carbs per day.
Net Carbs
Net carbs are the thing to watch on the keto diet. Net carbs can be calculated by taking the “total carbohydrates” minus the “fiber” and (sometimes) minus the “sugar alcohols”. Note that the “(sometimes) minus” is due to the fact that sugar alcohols may or may not spike your insulin and/or impact your blood sugar, it really depends on the person, and the particular sugar alcohol in question. You’ll need to experiment yourself to determine if a specific sugar alcohol impacts your blood sugar or not, if it does, then that type of sugar alcohol should be counted as a carb; and if not, it shouldn’t.
Why am I on keto?
My wife and I are both programmers and as such, we’re on our butts almost the entire day. I had always been a pretty skinny guy, at least through high school. I was a pretty consistent 145 pounds for each year of high school, but with the too much eating out, snacking, etc, I had made my way up to an overweight 195 pounds several times since then.
The last time I had hit this weight, I had taken up running to get in shape. This worked out great at the time! Back then, I had a 5 minute commute and no baby; in comparison to now with a 1+ hour commute, and 1 baby (with another on the way). Suffice it to say, I no longer have the leisurely 7 hours or so a week to spend on running, I’m doing at least that on my commutes, not even accounting for my (now) toddler Aaron.
Along came the keto diet. Kristen brought this up to me as a way for us to lose weight. We both did research, started listening to 2ketodudes podcast, and decided to give it a shot!
So what’s the story with keto? Well…
Ketosis
Ketosis is a state your body is in when burning fat to produce ketones, an alternate source to glucose to give your body energy. Ketosis is achieved when the body is taking in anywhere between 20–50g of net carbs a day. Once your body is in ketosis, it no longer has access to glucose, so ketones are produced and used as your body’s fuel source.
Wait, ketones, ketosis? I thought those were bad for you?!
Some people may have heard that ketones can smell sweet or like nail polish remover in your urine, and if they’re present it could be problematic. Ketones being present can be an indicator of ketoacidosis, which is not to be confused with ketosis. Ketoacidosis is generally attributed to type 1 diabetes complications. Ketoacidosis occurs when your body has too little insulin to handle the high amount of glucose in your blood.
So ketones in your blood can be bad, but if you’re following a keto diet, they’re expected and shouldn’t be problematic. Obviously, check with your doctor before doing any sort of diet change like keto.
Benefits of keto
Weight Loss
Weight loss is probably the most obvious benefit to keto if it was being considered as a diet. The weight loss is due to a few factors namely:
- Your body is using fat for fuel rather than carbs, if no fat is available due to recently eaten food, fat is broken down in your body for energy
- As you become fat adapted within the state of ketosis, your body’s mechanism for realizing it’s “full” allegedly can repair itself. There are some beliefs that when your insulin level is constantly high, that it can interfere with the body’s natural mechanism of knowing it’s full.
- Less snacking — because your insulin should overall be at lower levels on the diet, you might get less cravings for food.
Fixing insulin resistance
Insulin resistance is the body’s inability to use insulin as effectively as it should. Insulin is released into your body in response to food, but namely carbs. On the ketogenic diet, the amount of insulin your body needs to function is dramatically reduced. This reduction of insulin over time can help your body to become less resistant to it; not to mention the fact that high insulin has many health detriments associated with it. More information on insulin resistance can be found here:
https://www.healthline.com/nutrition/insulin-and-insulin-resistance
Mental Clarity
Your body is used to being powered by sugar, but there are some sources that state that ketones (the thing your body uses for energy on the ketogenic diet) are better for powering many of your organs, including brain. I’m not a nutritional scientist and don’t know how much truth there is to it, but a lot of people claim that when on keto your mind is sharper.
The Ketones Brain: Using a Keto Diet for Better Mental Health
Epilepsy
One of the reasons the keto diet was prescribed was actually due to epilepsy, not weight loss. The keytones powering your brain for whatever reason are apparently good for reducing seizures in children who have otherwise not responded to medication.
Ketogenic Diet
Polycystic Ovary Syndrome / Fertility
Kristen has polycystic ovary syndrome, or PCOS. This is something that can lead to carrying weight, especially around your stomach, and is associated with a difficulty in conception and carrying a baby to term. The keto diet can apparently help resolve some of the symptoms of PCOS. Additionally, some have had additional success with conceiving and carrying a baby to full term, if nothing else because of being a healthier weight!
The keto diet has also been attributed to healthier swimmers. I mentioned it earlier, but Kristen and I are expecting our second child in a few months, we found out we were pregnant just a few weeks/months into keto! Due to the diet, specifically the high fat, Kristen needed to drop keto, as the amount of fat we were having was not sitting well with those pregnancy aversions; but hopefully she’ll be able to pick it back up, and continue on our keto journey!
Can the Keto Diet Help Boost Fertility?
Diabetes
The keto diet is starting to be studied in type 2 diabetes, and now even type 1! I find it kind of strange that it’s taken so long for the diet to catch on for diabetes treatment, since the whole keto diet mantra is to have less of a need on insulin for your body to function. For type 1 diabetics, who can’t produce insulin, it seems like it only makes sense to have a diet that makes your body not need as much insulin.
https://diabetesstrong.com/ketogenic-diet-and-diabetes/
Meal planning
We used to eat out a lot; I mentioned it before, and I attribute it to a lot of Kristen and my weight gain. I’ve always been a cook, but my wife and I have always struggled with coming up with meals for the week.
For a while (prior to keto) we were doing a meal plan service — Blue Apron to be precise. We really loved what this service did for us, especially around the limited number of options to choose from, we could just choose. The most difficult part of meal planning for us, I think, but just the infinite number of things to choose from when planning out meals for the week.
I don’t recall if Blue Apron had a keto option or not, I know some of the meal planning services do; however it’s always an upcharge for keto, on an already expensive service. On Blue Apron I think we were doing 3 meals for 2 a week, at 60$ a week. Some of the meal prep/delivery services we were looking at charges 15$ a week more on top of that 60. That’s just too much!
So what do we do? It’s too much of a hassle to plan meals in the beginning of the week, and too expensive to do a keto meal plan service. Luckily, Kristen found an app call Mealime.
Mealime - Meal Planning App for Healthy Eating
Mealime more or less gave us what we loved about the meal delivery services in that we could just pick from a set of full meals, but without the cost. We can easily scale up or down the meals we’re choosing, and we can choose as many meals a week that we’d like. With Mealime we are able to save “favorites”, and can try many different meals, or stick with our normal gotos (or favorite! :D).
You’re able to tailor Mealime to your dietary restrictions, in our case keto. What kind of food can you eat with keto? Thankfully, a lot. Eating keto isn’t really all that different than eating a typical American diet; you just don’t have the starch with your meal.
Since fat is now your fuel source, you can eat all kinds of rich, fatty foods; foods that had you eaten on a normal diet you’d definitely be packing on the poundage. I’m eating more butter and steak than I ever have, and shedding the pounds! Note, be careful about too much red meat and butter and all that. Keto can apparently lead to higher cholesterol.
Anyway, back to Mealime and some of the stuff we eat. Here’s some of our “favorite” meals from Mealime:


You can probably tell, but we’re still eating pretty well. The food above is “more or less” exactly what we’d eat before, just with more butter, coconut oil, or avocado; minus the rice, potatoes, pasta, etc.
My results
I started 2018 at 195 pounds. Throughout the year, until we started keto around June or July, I had brought that down to 185. It’s now February 2019, and I’m down to 153–157, depending on the day, which I’ll get into in a bit.
I’m using a smart scale to track my progress, but unfortunately the first few weeks of keto my smart scale was not syncing, as our wifi information had changed and I didn’t think to update the scale. That being said, when I did update the scale, I started tracking my progress. Here is what my progress looks like right now:


The results:

I hit my goal of 160 pretty quickly, and have been maintaining around 153–157. This is crazy to me — just by changing the way I eat by eliminating carbs and upping fat, I dropped more fat and weight than I did when I was running 20+ miles a week!
At the start of keto, I made sure to keep my carbs closer to 20g, usually a bit under. For the first few weeks I started the day with bulletproof coffee — coffee that was blitzed together with butter and MCT oil (it’s really not as bad or weird as it sounds). For lunch I would either skip (on days that I was fasting), have a salad w/ avocado, or even pho! (Note, without noodles)

As stated above, we’d follow Mealime for our dinners, and often we’d have leftovers (which were great for lunch!). Another benefit to Mealime over our previous Blue Apron; with Blue Apron we’d never have leftovers, so it often just meant more cooking more often, that’s no good when you’re trying to save time and money!
Maintaining
At this point I am maintaining my weight, just keeping an eye on things. I generally stick to a keto diet between 5 and 6 days in a week, and indulge a bit with some carbs 1 or 2 days a week. The hardest part of keto to me, was not being able to eat a few of my favorite foods for a few months. At this point, since I’m at my goal weight, I have worked those foods back in a bit to treat myself. If you can’t enjoy your favorite foods once in a while, is it really worth it?
Of course my favorite foods: pho, ramen, sushi, and tacos, are pretty carb heavy. Sticking to these favorite foods once or twice a week, has allowed me to maintain ketosis, and my weight, pretty consistently.
I’ve been doing this for less than a year, but I’m hopeful that keeping a consistent one or two cheat days a week, will allow me to keep the weight off.
Something about cheat days, I don’t always even necessarily leave ketosis these days. I have a few times, to be sure, but not always. The nice thing about once you’re fat adapted, it’s much quicker to get back into ketosis than previously. It’s generally pretty obvious when I’ve left ketosis, as I’m usually around 5 pounds heavier than the day before’s weight; this is of course due to having enough carbs to start a glycogen store, where a lot of weight is stored in the form of water and glucose.
Resources
]]>